炸了!这届 ICLR 论文被指太“渣”?Goodfellow 围追堵截要说法

编者按:本文来自于微信公众号 “量子位”(微信公众号:QbitAI), 动点科技经授权发布。
搞机器学习的这帮人在Twitter上又炸了。
起因是一名叫Anish Athalye的小哥率先“放出狠话”。
“对抗样本防御仍是一个未解决的问题,三天前的ICLR接收论文中,7/8关于防御的论文已经被我们攻破。”
此外,Athaly还在GitHub上放出了自己的论文和repo支持自己的说法。
也就是说,他们认为这届深度学习顶会ICLR的相关论文太渣了?
不得了。
一时间,各方大神纷纷赶来或围观或质疑或膜拜,谷歌大脑Jeff Dean也前来看戏。
他们在吵什么?
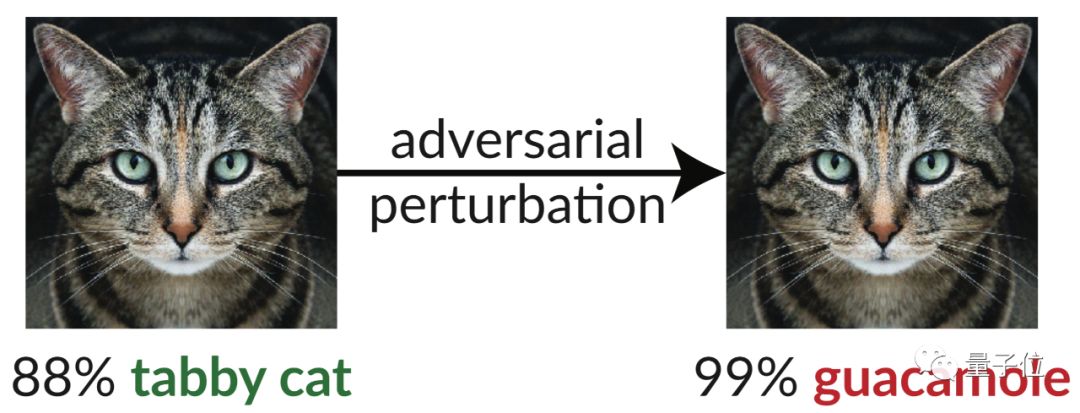
举个例子。在上面这张图片中,一张花斑猫的图像经过轻微扰乱后,就被骗过AI,被InceptionV3分类器错误的识别成了牛油果沙拉酱。

就是这么神奇。
人眼看起来完全不像的两类物体,怎么就被分类器混淆了呢?
早在2013年的论文Intriguing properties of neural networks中,一作Christian Szegedy就提出梯度下降的方法可以轻松合成出欺骗分类器的图像。
而这次Athalye等人这篇12页的论文中指出,当前大多数对抗样本防御方法依赖梯度混淆(obfuscated gradients),通过给attaker错误的梯度使基于梯度下降的对抗样本失效。这种防御方式可能会导致对对抗样本防御安全感的错误判断。
(相关论文:Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples https://arxiv.org/abs/1802.00420)
论文中指出,基于这种技术的防御已经是过去时了,他们的方法可以克服对梯度混淆的依赖。之后,他们研究了ICLR 2018接收的有关对抗样本防御的8篇论文论文,发现8个系统中的7个依赖于梯度混淆,并用新方法对这8篇ICLR论文中的方法进行测试,结果如下:

只有Aleksander Madry等人的方法在此攻击下准确率达到47%,其他7篇中提到的方法准确率甚至降为0%。
这么可怕么?!
来者不“善”
这位在Twitter上公开叫板顶会论文的小哥Anish Athalye究竟何许人也?
据LinkedIn和GitHub上的资料显示,小哥目前是MIT计算机科学专业的博士生,同时也在OpenAI实习,此前也曾是谷歌实习生。
有意思的是,去年12月在国内引发热议的“谷歌AI将乌龟认成步枪”事件,也是Athalye的杰作。
除了论文一作Anish Athalye外,其他两位作者也不是等闲之辈。Nicholas Carlini目前是UC伯克利计算机安全专业的博士生,David Wagner是他的导师。
去年3月,两人曾合力研发出小有名气的构建对抗样本的方法CW attack(The Carlini and Wagner),将论文Explaining And Harnessing Adversarial Examples中提到的攻击方式转化成更高效的优化问题。
Goodfellow围追堵截要说法
Paper和GitHub repo一出,把对抗样例攻击和防御这个领域一手拉扯大的Ian Goodfellow立刻坐不住了,在GitHub上连续提了两条意见(issue),跑到Reddit社区回帖,还在论文一作Anish Athalye的twitter下留了言,可谓处处围追堵截,要作者们放学别走,给个说法。
Goodfellow的意见总结起来,主要是两点。一是ICLR 2018一共接收了至少11篇关于对抗样例防御的论文,这篇论文只用了8篇,需要说清楚并非全部;二是这篇论文提出的“混淆梯度(obfuscated gradients)”,简直就是给“著名”的“梯度掩码(gradient masking)”起了个别名。
我们来分别看一下。
第一条意见很简单,主要是因为Athalye等人行文不严谨引起的。
在论文中,他们说从ICLR 2018接收的对抗样例防御论文中排除了3篇,其中两篇有已经证实的防御方法,一篇只针对一种黑盒情况。但是在论文摘要和GitHub repo里没有说清楚。Goodfellow建议严谨地写成“所有未经证实的白盒场景下的防御”。
几位作者也说,明后天上传更新版论文,会改正这个问题。
第二条意见就严重多了:Goodfellow指责这篇论文提出的混淆梯度并非独创,和前人(包括他自己)讲了又讲的“梯度掩码”是一样的。
这就比较尴尬了。
二作Nicholas Carlini在GitHub上作出了比较“柔软”的回应,大致意思是我一开始也纠结要不要叫这个名字,但后来觉得,混淆梯度和梯度掩码还是有区别的,梯度掩码保留了大部分梯度信号,我们说的混淆梯度,整体上梯度都是复杂的。
说他的回应“柔软”,主要是因为他在其中承认“可能这个决定是错误的”、“如果研究人员们认为我错了,想叫梯度掩码,我也OK”。
除了Goodfellow之外,另一位研究者Florian也和他们讨论过这个问题。
为了让后生晚辈更深刻地理解梯度掩码,Goodfellow还给Athalye等人推荐了一串参考文献:
Practical Black-Box Attacks against Machine Learning
Nicolas Papernot, Patrick McDaniel, Ian Goodfellow, Somesh Jha, Z. Berkay Celik, Ananthram Swami
https://arxiv.org/abs/1602.02697
Attacking Machine Learning with Adversarial Examples
https://blog.openai.com/adversarial-example-research/
Ensemble Adversarial Training: Attacks and Defenses
Florian Tramèr, Alexey Kurakin, Nicolas Papernot, Ian Goodfellow, Dan Boneh, Patrick McDaniel
https://arxiv.org/abs/1705.07204
Gradient Masking in Machine Learning
Nicolas Papernot
https://seclab.stanford.edu/AdvML2017/slides/17-09-aro-aml.pdf
另外,你们说研究了ICLR 2018接收的所有防御论文,但是有一篇专门解决梯度掩码问题的,就给漏掉了:
Ensemble Adversarial Training: Attacks and Defenses
https://openreview.net/forum?id=rkZvSe-RZ
老师留作业啦 щ(゚Д゚щ)
当然,还有不少人的关注点在于,这个GitHub repo虽然已经火了起来,但其实……只包含readme,代码还没放出来。作者们说,如果有研究者想看源代码,可以找他们要;他们也会尽快将清理干净的源代码放出来。
Twitter效应
这次激烈的大讨论,意义已经不仅限于某一事件。
“当我在Twitter上讨论对抗样例的时候,其实希望这些可以更早地在OpenReview上发生。我们需要一个更好的机制来处理现代的同行评审和更正”,斯坦福大学博士生Ben Poole说。
多伦多大学助理教授Daniel Roy补充说,他在OpenReview上的互动其实挺多,但基本没什么帮助,Twitter能够吸引注意力,但可能也不是解决问题的最佳场所。
Kaggle前任CEO、Fast.ai创始人Jeremy Howard看到这些讨论时,评论说:我认为arXiv上的预印版论文加上Twitter上的讨论是同行评审的好方法,比OpenReview的时效性和参与度都更高。
可以看出来,Jeremy Howard对Twitter上讨论学术还是挺推崇的。
他进一步指出,Twitter虽然不是唯一的场合,但经常能够触及很多OpenReview上没有的研究人员,而且并非只有名人的声音得到传播放大。
“我只想说:请接受并欢迎这个伟大的社区”,Jeremy Howard说。
确实如此。前不久,谷歌传奇人物Jeff Dean终于开通了Twitter账号,而且一开不可收拾,活跃度非常高。这次的讨论,Jeff Dean也转发参与了。
不过更有意思的是上次,Jeff Dean团队发表了一篇关于深度学习应用于电子病历的论文。不过随即就有人尖锐的指出,这篇论文“令人震惊”:没有提及任何人在这方面的研究。
“这真是太丢脸了”,Jeff Dean随后回复,并承诺会立刻更新论文。
更充分的交流,这也是社交网络的意义。