字节跳动公司宣布推出一种名为 INFP 的人工智能系统,能够让静态的人物肖像照片通过音频输入实现 “说话” 和反应。与传统技术不同,INFP 无需手动指定说话和倾听的角色,系统可以根据对话的流动自动判断角色。该系统通过两个步骤工作:首先提取人类对话中的运动细节,其次将音频转换为自然的运动模式。字节跳动的 DyConv 数据集包含超过200小时的高质量对话视频,帮助提升系统性能。
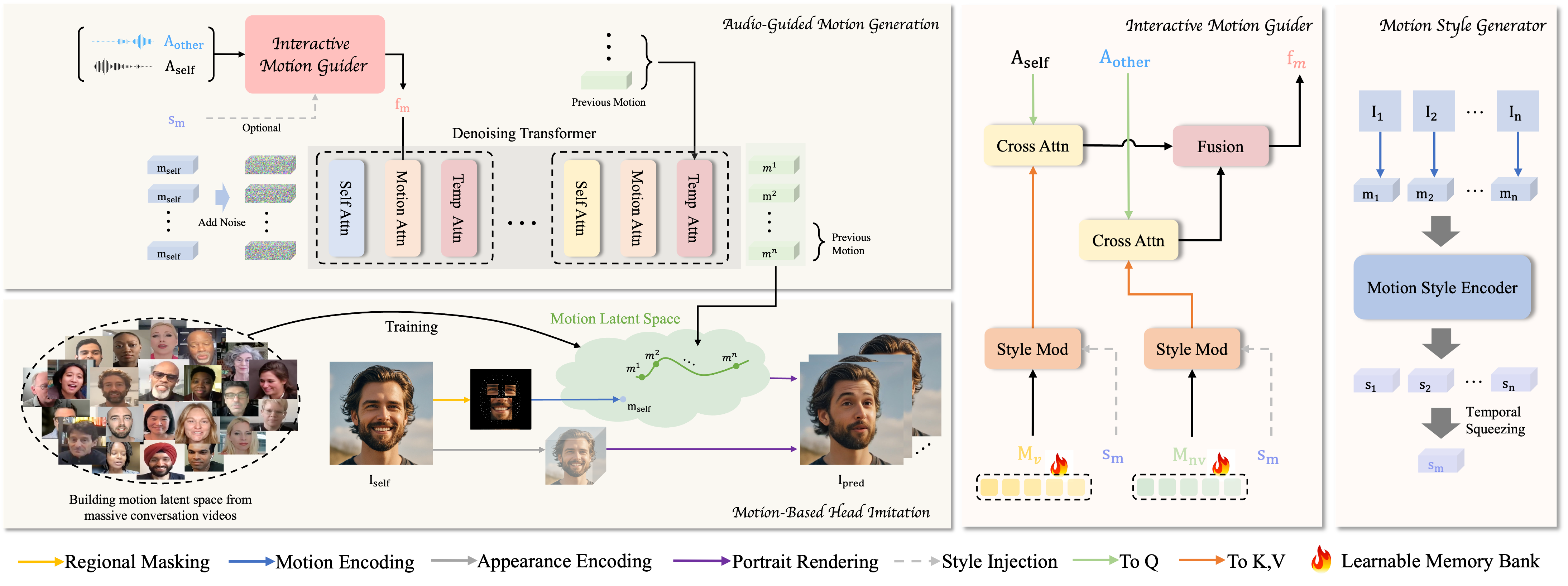
字节跳动表示,INFP 在多个关键领域的表现优于现有工具,特别是在与语音匹配的唇部运动、保留个体面部特征以及创造多样化自然动作方面。此外,该系统在生成仅听对话者的视频时同样表现出色。



