多智能体对抗作为决策AI中重要的部分,也是强化学习领域的难题之一。为丰富多智能体对抗环境,OpenDILab(开源决策智能平台)开源了一款多智能体对抗竞技游戏环境——Go-Bigger。同时,Go-Bigger还可作为强化学习环境协助多智能体决策AI研究。
与风靡全球的agar.io、球球大作战等游戏类似,在Go-Bigger中,玩家(AI)控制地图中的一个或多个圆形球,通过吃食物球和其他比玩家球小的单位来尽可能获得更多重量,并需避免被更大的球吃掉。每个玩家开始仅有一个球,当球达到足够大时,玩家可使其分裂、吐孢子或融合,和同伴完美配合来输出博弈策略,并通过AI技术来操控智能体由小到大地进化,凭借对团队中多智能体的策略控制来吃掉尽可能多的敌人,从而让己方变得更强大并获得最终胜利。

四类小球,挑战不同决策路径
Go-Bigger采用Free For All(FFA)模式来进行比赛。比赛开始时,每个玩家仅有一个初始球。通过移动该球,玩家可吃掉地图上的其他单位来获取更大的重量。每个队伍都需和其他所有队伍进行对抗,每局比赛持续十分钟。比赛结束后,以每个队伍最终获得的重量来进行排名。
在一局比赛中共有分身球、孢子球、食物球、荆棘球四类球。分身球是玩家在游戏中控制移动或者技能释放的球,可以通过覆盖其他球的中心点来吃掉比自己小的球;孢子球由玩家的分身球发射产生,会留在地图上且可被其他玩家吃掉;食物球是游戏中的中立资源,其数量会保持动态平衡。如玩家的分身球吃了一个食物球,食物球的重量将被传递到分身球;荆棘球也是游戏中的中立资源,其尺寸更大、数量更少。如玩家的分身球吃了一个荆棘球,荆棘球的大小将被传递到分身球,同时分身球会爆炸并分裂成多个分身。此外,荆棘球可通过吃掉孢子球而被玩家移动。

分身球
团队紧密配合,实现合理重量传递
在Go-Bigger中,团队内部的合作和外部的竞技对于最终的成绩至关重要。因此,Go-Bigger设计了一系列的规则来提高团队所能带来的收益。由于玩家的分身球重量越小,移动速度越快,更多的分身可以保证快速发育,但是会面临被其他玩家吃掉的风险。同时,冷却期的存在使得玩家无法靠自身摆脱这样的风险。因此,同一队伍中不同玩家的配合尤为关键。
为便于团队内玩家的配合,Go-Bigger设置了玩家无法被同队伍完全吃掉的规则。Go-Bigger还设置了单个分身球的重量上限和重量衰减,使得单一分身球无法保持过大重量,迫使其分裂以减少重量损失。在游戏后期,团队内部的重量传递会显得至关重要,合理的重量传递可以保证团队在与其他队伍对抗时获得更大的优势。
支持RL环境,提供三种交互模式
此外,为帮助用户在强化学习领域的多智能体策略学习,Go-Bigger也提供了符合gym.Env标准的接口供其使用。在一局游戏中,Go-Bigger默认设置含有20个状态帧和5个动作帧。每个状态帧都会对当前地图内所有单位进行仿真和状态处理,而动作帧会在此基础上,附加对单位的动作控制,即改变单位的速度、方向等属性,或使单位启用分裂、发射或停止等技能。
为了更方便地对环境进行探索,Go-Bigger还提供了必要的可视化工具。在与环境进行交互的时候,可以直接保存本局包含全局视角及各个玩家视角的录像。此外,Go-Bigger提供了单人全局视野、双人全局视野、单人局部视野三种人机交互模式,使得用户可以快速了解环境规则。
三步走,快速搭建强化学习baseline
算法baseline的目的是验证某个问题环境使用强化学习算法的初步效果,对各个环节的信息做简单梳理和分析,熟悉之后便可轻松上手比赛,在环境、算法、算力上逐步增加复杂度,设计迭代效果更强的智能体。
Go-Bigger环境的强化学习算法baseline主要分为环境瘦身、基础算法选择、定制训练流程三部分。其中,环境瘦身即将原始游戏环境简化成适用于强化学习的标准环境格式;基础算法选择指根据环境的基本信息选择合理的基础RL算法;定制训练流程指根据环境的特殊特征定制训练流程。
- 环境瘦身
- 人类视角的Go-Bigger(上)S. 翻译成游戏引擎中的结构化信息(下):

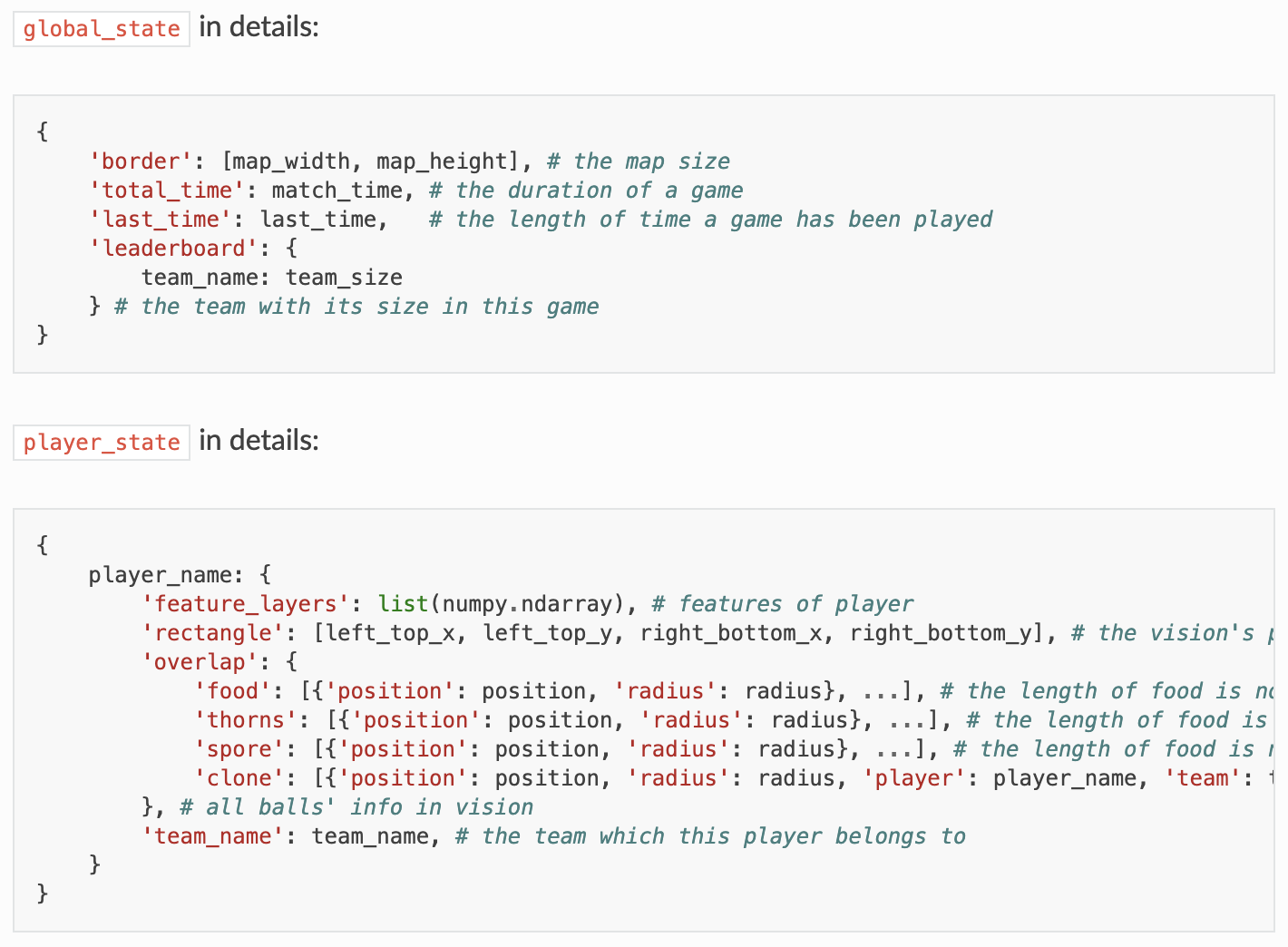
这些人理解起来很简单的数据表示,对计算机和神经网络却非常不友好,因此需要专门对这些信息做一定的加工,并根据强化学习的特性设置成标准的强化学习环境观察空间。
- 特征工程:
- 原始的游戏数据需要表达游戏内容,其数值范围波动便会较大(比如从几十到几万的球体大小),直接将这样的信息输入给神经网络会造成训练的不稳定,所以需要根据信息的具体特征进行一定的处理(比如归一化,离散化,取对数坐标等等)。
- 对于类别信息等特征,不能直接用原始的数值作为输入,常见的做法是将这样的信息进行独热编码,映射到一个两两之间距离相等的表示空间。
![]()
- 对于坐标等信息,使用绝对坐标会带来一些映射关系的不一致问题,相对坐标通常是更好的解决方式。
- 从RGB图像到特征图像层

直接将原始的RGB 2D图像信息输入神经网络,尽管结果尚可,但需要更多的数据、更长的训练时间,以及更复杂的训练技巧。更为简明并有效的方式是进行“升维”,即将耦合在一起的图像信息离解成多个分离的特征图像层。最终根据游戏内容定义出具体的特征图像层,并区分各个玩家的局部视野,拼接后构成总体的特征图像层。下图为一玩家视野中食物球的特征图像层:

- 可变维度
Go-Bigger环境中存在很多可变维度的地方,为了简化,baseline环境中强行截断了单位数量,用统一的方式来规避可变维度问题。
- 设计动作空间
Go-Bigger对于人类来说操作起来十分简单,包括上下左右QWE,这些基本的按键组合起来便可以诞生出许多有趣的操作,如十面埋伏、大快朵颐等。但是,游戏引擎中实际的动作空间是这样的(动作类型 + 动作参数):
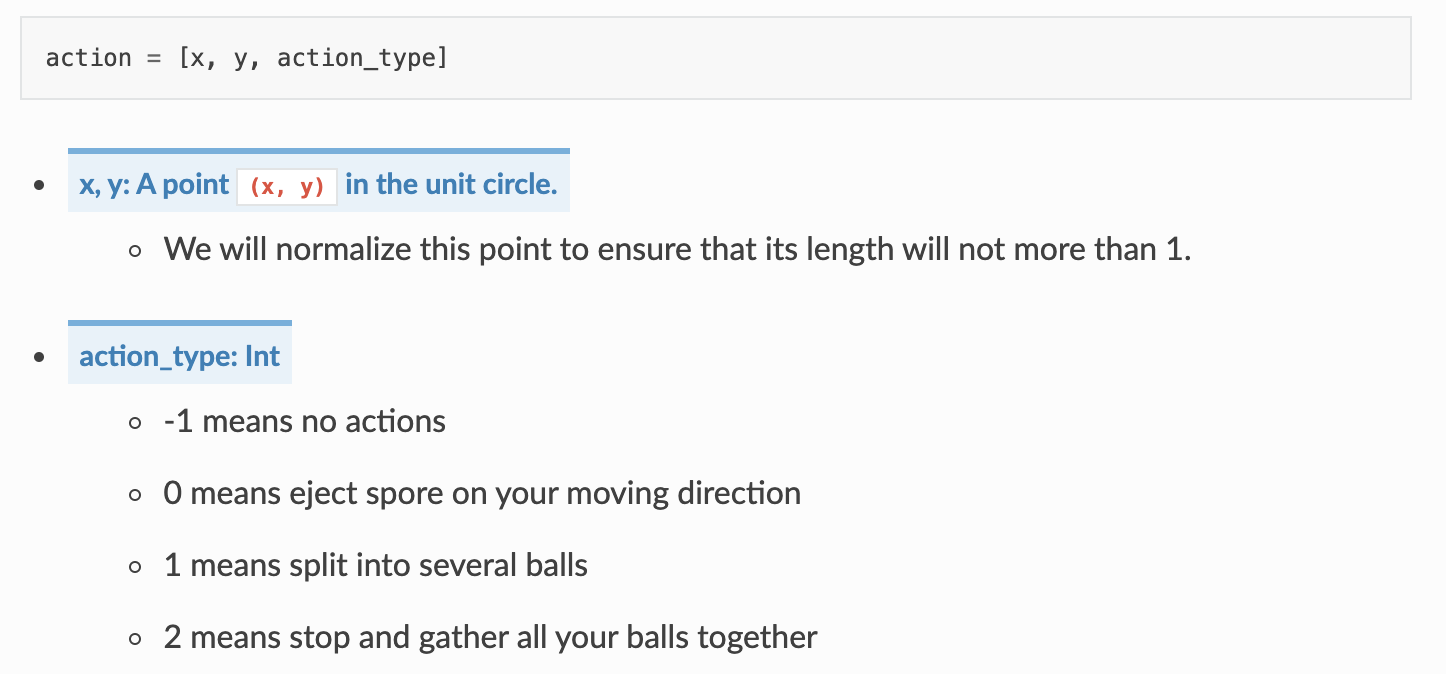
游戏引擎的这种形式在强化学习中被称作混合动作空间,也有相应的算法来处理该问题。但基于baseline一切从简这一核心,通过使用比较简单粗暴的离散化处理,将连续的动作参数(x,y坐标)离散化为上下左右四个方向。针对动作类型和动作参数的组合,也简单使用二者的笛卡尔积来表示,最终将环境定义为一个16维的离散动作空间。
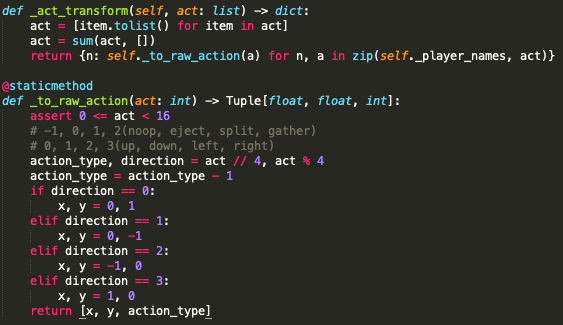
- 设计奖励函数
奖励函数定义了强化学习优化的目标方向。Go-Bigger是一项关于比谁的队伍更大的对抗游戏,因此奖励函数的定义也非常简单,即相邻两帧整个队伍的大小之差。
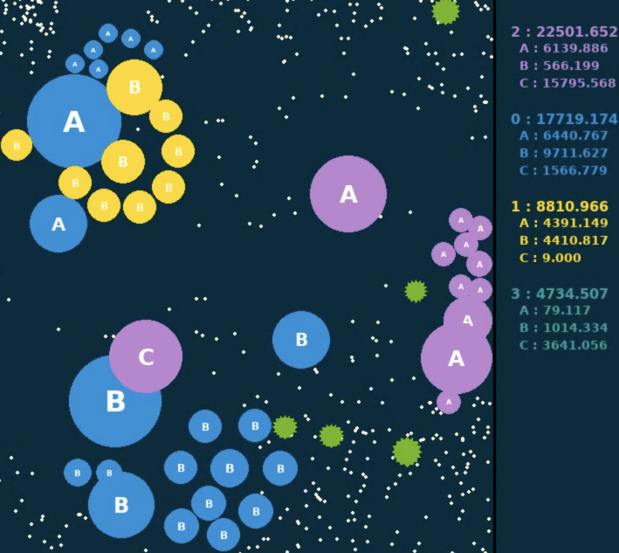
如下图所示两张表示相邻两个动作帧,右侧计分板显示各个队伍实时的大小数值,将当前帧的大小减去上一帧的大小,就定义得到了奖励值。而对于整场比赛,则使用每一步奖励的累加和作为最终的评价值。评价值最大的队伍,将赢得本局比赛。此外,在训练时,还通过缩放和截断等手段将奖励值限制在[-1, 1]范围内。
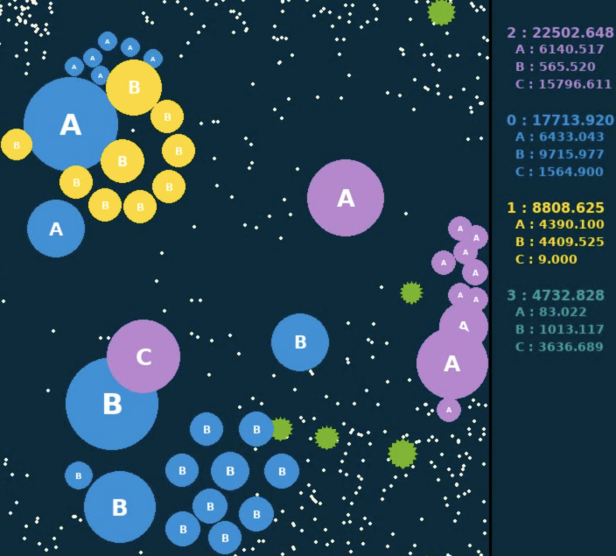
- 基础算法选择
在完成对RL环境的魔改之后,会呈现如下基本信息:
- 多模态观察空间:图像信息 + 单位属性信息 + 全局信息
- 离散动作空间:16维离散动作
- 奖励函数:稠密的奖励函数,且取值已经处理到[-1, 1]
- 终止状态:并无真正意义上的终止状态,仅限制比赛的最长时间
对于这样的环境,可用最经典的DQN算法 + 多模态编码器神经网络来实现。对于各种模态的观察信息,使用数据对应的经典神经网络架构即可。例如,对于图像信息,选择一个带降采样的卷积神经网络将2D图像编码为特征向量;对于单位属性信息,需要建模各个单位之间的联系,获得最终的单位特征向量;对于全局信息,则使用由全连接层构成的多层感知机。在各部分编码完成之后,将三部分的特征拼接在一起,将构成时间步的观察特征向量,以复用最经典的Dueling DQN结构。以特征向量为输入,输出这一步选择16个动作的Q值,并使用N-step TD损失函数即可完成相应训练的优化。完整的神经网络结构如下图所示。
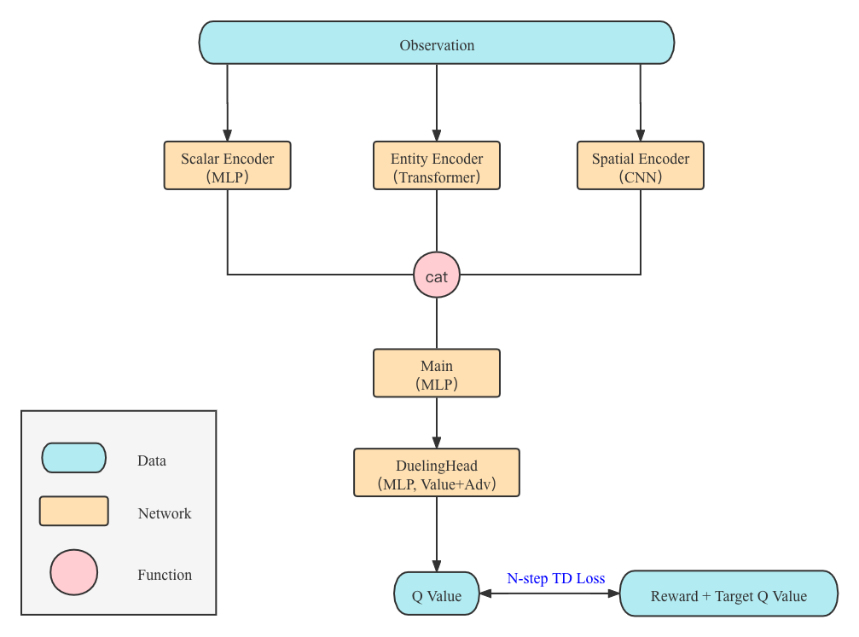

- 定制训练流程
DQN通常只用来解决单智能体的问题,而在Go-Bigger中一支队伍会存在多个玩家,且一局比赛为多个队伍混战,因此会涉及多智能体之间合作和对抗等问题。在多智能体强化学习领域,针对该问题可展开诸多的研究方向,但为简化设计Go-Bigger使用了Independent Q-Learning (IQL)+ 自我对战(Self-Play)的方式来实现训练流程。
例如,对于一个队伍中的多个智能体,团队的最终目标是让整个队伍(总体积/总体量/总重量)的大小最大,因此在baseline中可使用IQL算法来实现,以高度并行化地实现整个优化过程;对于实际一局比赛中存在多个智能体的情况,则可使用朴素的自我对战(Self-Play)这一相当简单且非常节省算力的方式来参与比赛。评测时,会将随机机器人和基于规则的机器人作为比赛的对手,测试验证目前智能体的性能。
Tips:
- 使用更高级的自我对战(Self-Play)算法(比如保存智能体的中间历史版本,或使用PFSP算法);
- 构建League Training流程,不同队伍使用不同的策略,不断进化博弈;
- 设计基于规则的辅助机器人参与到训练中,帮助智能体发现弱点,学习新技能,可作为预训练的标签或League Training中的对手,也可构造蒸馏训练方法的老师,请玩家尽情脑洞。
从零开始实现上述算法和训练流程非常复杂,而通过决策智能框架DI-engine(https://github.com/opendilab/DI-engine)可大大简化相应内容。其内部已经集成了支持多智能体的DQN算法实现和一系列相关诀窍,以及玩家自我对战和对抗机器人的训练组件,只需实现相应的环境封装,神经网络模型和训练主函数即可(详细代码参考https://github.com/opendilab/GoBigger-Challenge-2021/tree/main/di_baseline)。
几个有意思的发现
通过上述简单基线算法训练出来的初级AI在在发育阶段会将球尽量分开,以增大接触面加快发育;在面对潜在的危险时,会避开比自身大的球,并使用分裂技能加快移动速度,防止被吃掉。这些操作都是在人类玩家的游戏过程中经常用到的小技巧。
为了进一步推动决策智能相关领域的技术人才培养,打造全球领先的原创决策AI开源技术生态,OpenDILab(开源决策智能平台)将发起首届Go-Bigger多智能体决策AI挑战赛(Go-Bigger: Multi-Agent Decision Intelligence Challenge)。本次比赛将于2021年11月正式启动,使用由OpenDILab开源的Go-Bigger(https://github.com/opendilab/GoBigger)游戏环境。希望集结全球技术开发者和在校学生,共同探索多智能体博弈的研究。欢迎对AI技术抱有浓厚兴趣的选手踊跃参加,和全球的顶尖高手一决胜负!



